本文的 GPUStack 版本为 v0.6.0 (3e1a04a),对应commit 的完整 hash 值为 3e1a04ad9a1649205cfee926895c7f3b1ded2e17
GPUStack
是一个用于运行 AI 模型的开源 GPU 集群管理器,文档地址在这里
。该项目采用 Python 编写,运行pip install gpustack即可安装(python 版本需要在 3.10 到 3.12 之间),使用gpustack start --data-dir ./data --port 49001启动服务,浏览器访问http://ip:49001输入用户名密码就可以进入界面。
GPUStack 在其仓库的 README 里面列出了一些 Key Features,其中比较重要的如下所示,本文也将结合源代码来分析 GPUStack 是如何实现这些 features 的:
- 广泛的硬件兼容性:支持管理 Apple Mac、Windows PC 和 Linux 服务器上不同品牌的 GPU。
- 广泛的模型支持:从大语言模型 LLM、多模态模型 VLM 到 Diffusion 扩散模型、STT 与 TTS 语音模型、文本嵌入和重排序模型的广泛支持。
- 异构 GPU 支持与扩展:轻松添加异构 GPU 资源,按需扩展算力规模。
- 分布式推理:支持单机多卡并行和多机多卡并行推理。
- 多推理后端支持:支持 llama-box(基于 llama.cpp 和 stable-diffusion.cpp)、vox-box 和 vLLM 作为推理后端。
- 轻量级 Python 包:最小的依赖和操作开销。
- OpenAI 兼容 API:提供兼容 OpenAI 标准的 API 服务。
- 用户和 API 密钥管理:简化用户和 API 密钥的管理流程。
- GPU 指标监控:实时监控 GPU 性能和利用率。
- Token 使用和速率统计:有效跟踪 token 使用情况,并管理速率限制。
整体架构
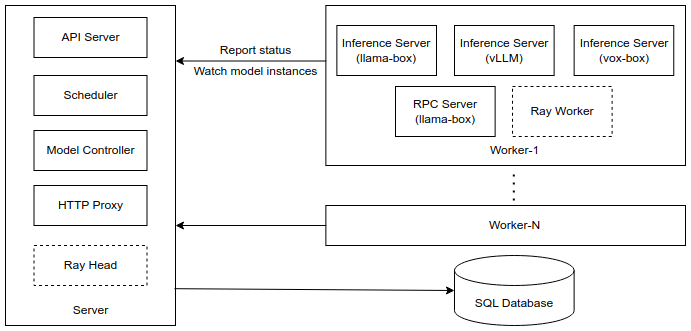
GPUStack 的整体架构如上图所示,server 负责接受请求、与数据库交互和进行调度,每个 worker 负责调用不同的推理后端来运行大模型,在运行时所有通信都通过发送 http 请求完成。
分布式推理
如之前的架构图所示,GPUStack 整体是个主从架构,启动 worker 时可以通过配置参数--server-url来让 worker 注册到指定的 server 上。
在执行任务时,GPUStack 的任务分配流程主要包括两个步骤:评估模型资源使用情况和进行任务调度。
评估资源使用情况
评估资源使用情况主要是估计模型需要使用的显存并和系统的显存对比,不同的推理后端采用不同的显存计算公式,对于 llama-box 而言,系统使用工具gguf-parser
进行估算,而对于 vLLM 则使用公式GPU Memory (GB) = Number of Parameters (B) * 2 * 1.2 + 2估算,同时还使用参数--gpu-memory-utilization控制模型最多占用 GPU 显存的百分之多少(默认 90%),相关代码见gpustack/scheduler/evaluator.py文件。
对于如何检测系统资源使用情况,GPUStack 的做法是调用命令行参数来解析 😄,不同品牌的设备调用不同的命令行和解析,包括nvidia-smi、npu-smi、fastfetch、rocm-smi等,相关代码可以见项目的gpustack/detectors目录下代码。
这里在看代码的时候发现,在估算资源是否够用时会调用evaluate_model_with_cache函数,这里会将之前估算的结果缓存起来,ttl=3600s,这里感觉很不合理,系统状态实时在变化,不应该缓存这种计算结果,所以在运行 GPUStack 是可以设置环境变量GPUSTACK_MODEL_EVALUATION_CACHE_TTL=0禁用这部分缓存。
调度任务
系统再调度方面的实现步骤是:
- 初始化一个异步第调度任务
- 该调度任务获取当前所有待调度的模型实例
- 每个模型的调度同样是一个异步任务,将所有模型的任务聚合执行
调度过程中,系统会依次进行过滤、选择候选者和打分三个步骤,最终选择分值最高的候选者进行部署。
过滤
过滤主要有下面三个过滤器(代码对应在gpustack/policies/worker_filters目录下):
- GPUMatchingFilter:根据前端部署时选择的 GPU 选择器筛选出带有指定 GPU 的 worker(GPU 选择器最终会存储为形如"worker_name:device:gpu_index"的文本,例如"gpu-development:cuda:0");

- LabelMatchingFilter:根据标签筛选机器,在前端可以给各个 wroker 打标签,每个标签是一个键值对,例如"os:linux";

- StatusFilter:筛选所有状态为 READY 的 worker。
选择候选者
选择候选者的方法签名为select_candidates,主要是根据资源使用情况来进行选择,确保模型实例可以在所选节点上运行而不会超出资源限制,不同推理后端的实现不同。目前有 gguf(llama-box)、vox-box 和 vLLM 三种,具体代码在gpustack/policies/candidate_selectors目录下。虽然三种后端的实现不同,但是大体上遵循下面优先级进行选择:
find_single_worker_single_gpu_full_offloading_candidates:单个工作节点上使用单个 gpu 完全卸载,性能最好;find_single_worker_multi_gpu_full_offloading_candidates:单个工作节点上使用多个 gpu 完全卸载模型;find_multi_worker_multi_gpu_candidates:使用多个节点上的多个 gpu 卸载模型;find_single_worker_partial_offloading_candidates:在单个工作节点上将模型分别卸载到 gpu 和 cpu 上;find_single_worker_cpu_candidates:使用单个节点上的 CPU 卸载模型。
llama-box 实现了上述所有选择逻辑
vLLM 实现了 1、2、3
vox-box 实现了 1 和 5
打分
在调度时的打分主要是根据不同的 placement strategy 进行评估,相关代码在gpustack/policies/scorers/placement_scorer.py中,目前有两个策略:
-
SPREAD 策略,SPREAD 策略的目标是将工作负载均匀分布到多个节点和 GPU 上,评分级别由高到低为:
- 最高级别(100 分):节点上没有任何模型实例
- 第二级别(90-100 分):节点上只有其他模型的实例
- 第三级别(80-90 分):节点上只有当前模型的实例
- 第四级别(70-80 分):节点上同时存在当前模型和其他模型的实例
对于 GPU 评分,会在基础分上根据各 GPU 上已有实例数量增加额外分数。额外分数计算公式为:
each_gpu_max_score / (instance_count + 1) -
BINPACK 策略,BINPACK 策略的目标是将工作负载集中到尽量少的节点上,基于资源利用率计算评分。考虑因素包括:
- 资源权重:VRAM(显存)权重为 2,RAM(内存)权重为 1
- 扩展模式:
- SCALE_UP:资源请求量/可用资源量
- SCALE_DOWN:资源请求量/(可用资源量+资源请求量)
评分过程会区分 CPU、单 GPU 和多 GPU 场景,对于多 GPU 会选择得分最高的 GPU 作为最终得分。
这两种策略适用于不同的场景:SPREAD 适合确保服务高可用性,BINPACK 适合提高资源利用率。
多推理后端
在调度之后就是实际运行大模型了,回忆一开始的的架构图,每个 worker 会包含 Inference Server,运行时是通过调用 Inference Server (实际上是通过命令行执行二进制文件)启动大模型。推理的代码在gpustack/worker/backends目录下,不同的模型使用不同的推理后端通过start方法启动,在start内的主要工作是拼接终端命令然后执行,在拼接命令前代码内会设置环境变量来指定运行模型的 gpu(gpustack/worker/backends/base.py的get_inference_running_env函数),例如如果是 llama-box 则会拼接出一个形如下面的指令:
/home/guochenxu/miniconda3/envs/gpustack10/lib/python3.10/site-packages/gpustack/third_party/bin/llama-box/llama-box \
--host 0.0.0.0 --embeddings \
--gpu-layers -1 --parallel 4 \
--ctx-size 8192 --port 40011 \
--model ./data/cache/model_scope/gpustack/stable-diffusion-v3-5-medium-GGUF/stable-diffusion-v3-5-medium-FP16.gguf \
--alias stable-diffusion-v3.5-medium --no-warmup \
--images --image-vae-tiling --tensor-split 1 \
--image-no-text-encoder-model-offload
当机器上有多个 gpu 时需要设置环境变量CUDA_DEVICE_ORDER=PCI_BUS_ID,否则用可能不会匹配到正确的 gpu,具体见issue #1952
。
其他 feature
除了上面两个,GPUStack 官网上还有很多其他 feature,但目前感觉这些和 GPUStack 并没有什么关系,例如“广泛的硬件兼容性”、“广泛的模型支持”等基本上都是推理后端实现的功能,如前文所述,GPUStack 所做的只是在进行了一系列筛选兜底后运行终端指令让推理后端完成任务,所以本文并没有分析这些 feature 的实现。
总结
笔者最后结合本人对大模型的浅显认知以及对 GPUStack 源码的简要了解,对 GPUStack 下一个定义:GPUStack 本质上只能算是个胶水,简化了模型部署流程以及缝合了各家推理后端。不过当然这这个定义只是针对大模型的部分,对于分布式部分的 GPUStack 的源码,如:进程间的通信、事件监听机制、对代码的抽象以及还没有看到的多台机器的数据同步等,还是让笔者受益良多的。
